
Guru Vachan — Sacred Text Search Engine
Yogoda Satsanga Society devotees needed a way to search Paramahansa Yogananda's teachings by concept — not just by keyword. We built Guru Vachan, a search engine that uses AI to understand spiritual questions and retrieve the exact passages where Guruji addressed them. The critical constraint: the AI must never paraphrase, interpret, or generate spiritual content. Every word the user sees comes directly from the indexed books, byte-for-byte.
Paramahansa Yogananda's teachings span dozens of books — thousands of pages covering meditation, devotion, karma, consciousness, and daily living. A devotee wondering 'How do I overcome restlessness in meditation?' might find the answer in the Autobiography, in a collection of prayers, or in a commentary on the Bhagavad Gita. Finding the right passage means searching across the entire corpus, not just one book.
Typical AI chatbots were not an option. They paraphrase, summarize, and hallucinate — all unacceptable when handling sacred text. Devotees need Guruji's exact words, not a machine's interpretation of them. Many books also contain words by other authors — forewords, prefaces, quoted verses — and misattributing those to Yogananda would be deeply disrespectful. The system had to be transparent about who said what, always.
Cost was another constraint. This is seva — volunteer service for a spiritual community, not a funded startup. The entire system needed to run for under $10/month, with no compromises on search quality or passage fidelity.
We designed a strict separation: the AI handles understanding and retrieval, but never touches the content itself. The search pipeline is a 9-node LangGraph workflow. When a user asks a question, GPT-4o-mini classifies the intent (concept search, verse lookup, off-topic, inappropriate) — spending about $0.0001 per query. Then the system searches Qdrant using both dense vectors (OpenAI text-embedding-3-large, 3072 dimensions) and sparse vectors simultaneously, covering both meaning-based and keyword-based matches.
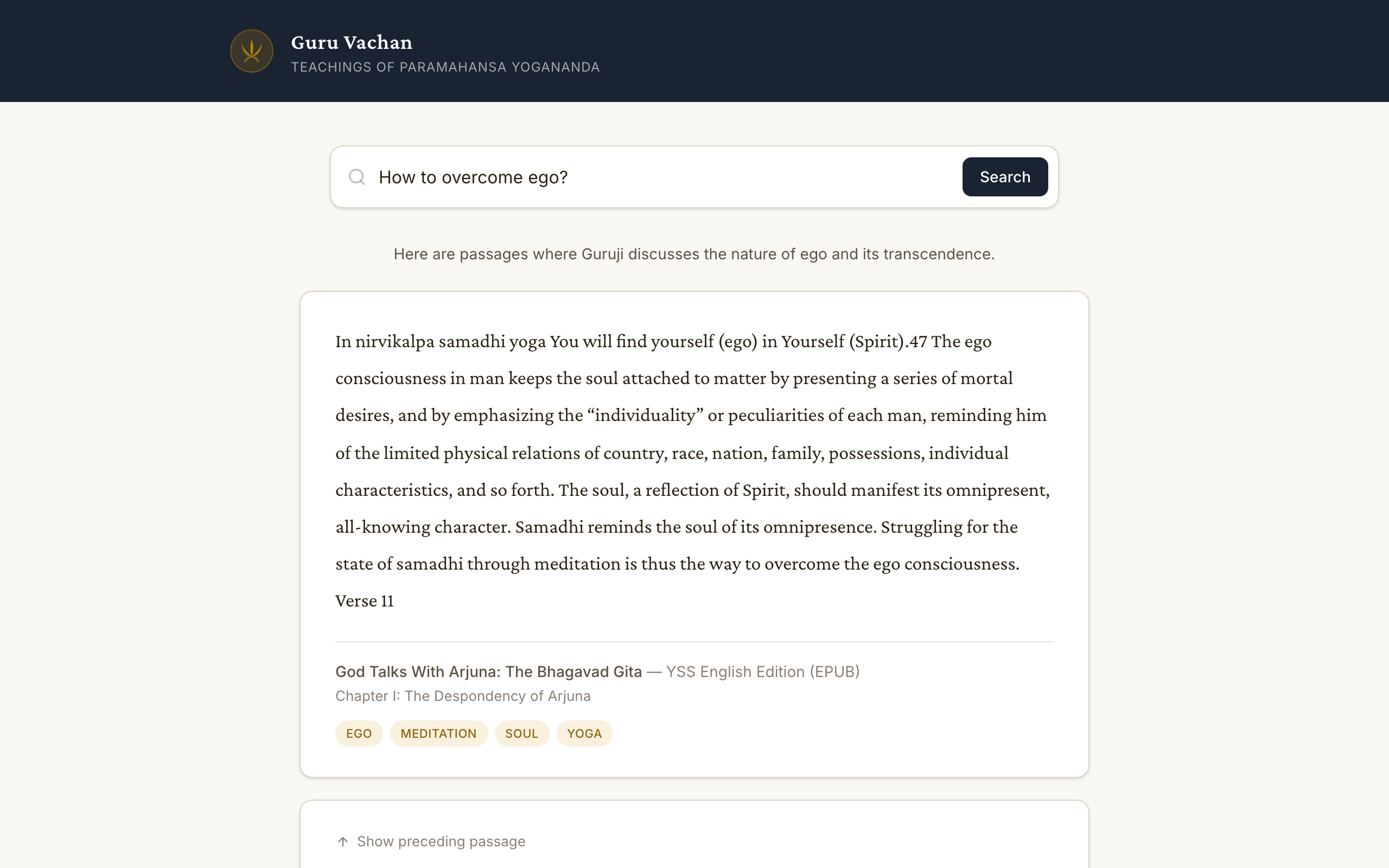
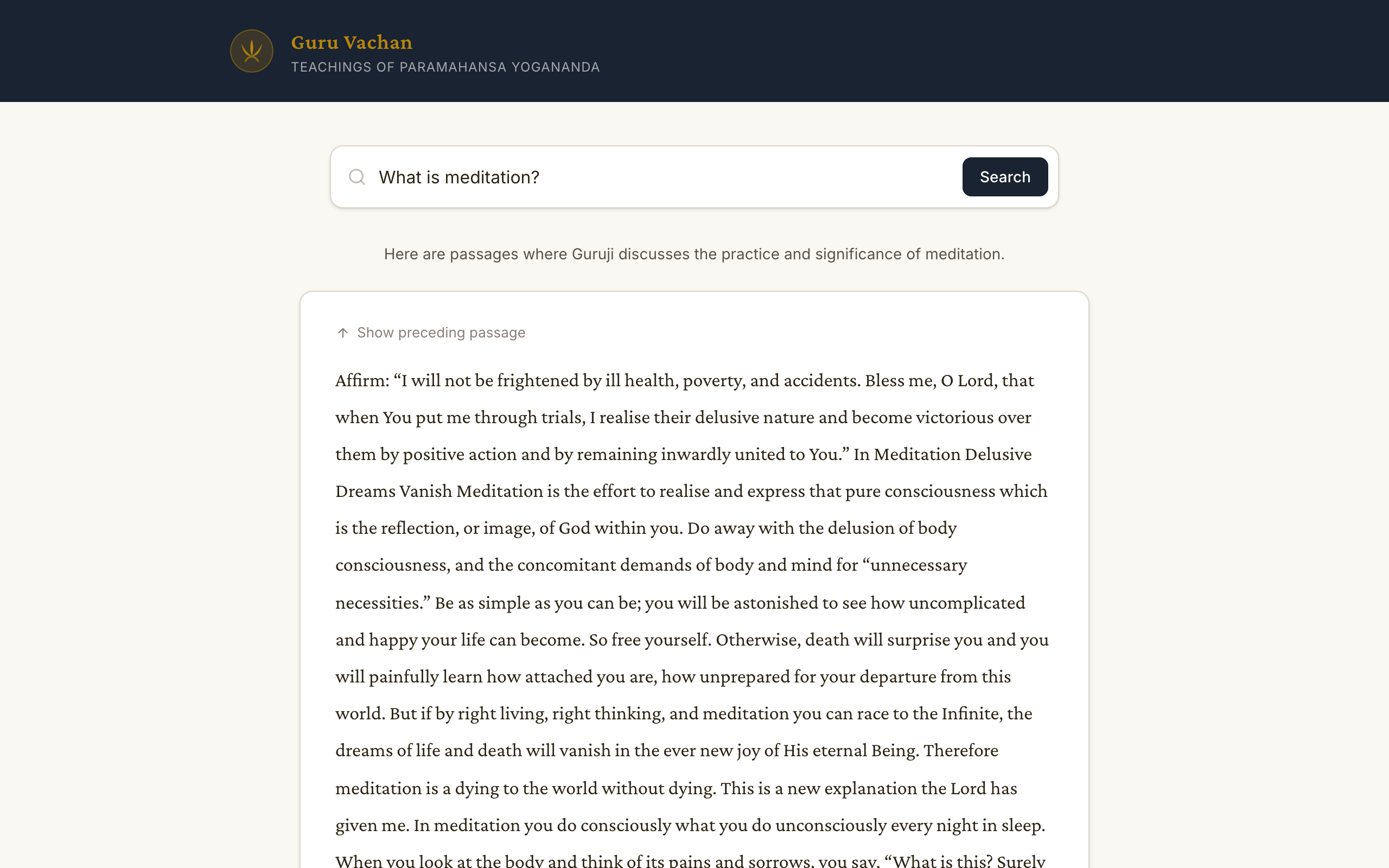
Results pass through a Cohere reranker that scores each passage against the original question, filtering out weak matches. Surviving passages get context expansion — the system retrieves neighboring chunks from the same chapter so the user can read surrounding text without leaving the page. Finally, the format node assembles the response with a one-line neutral framing (capped at 140 characters, validated by automated tests) and the passages themselves, passed through byte-for-byte with no transformation.
The ingestion pipeline (extract, chunk, enrich, embed, index) processes uploaded books with integrity checks at every stage: chunks must be 80-700 words, must not start mid-sentence or end without terminal punctuation, and each chunk carries attribution metadata identifying the actual speaker when it differs from the book's primary author. A Playwright test suite enforces that rendered passage length equals source passage length — no truncation, no ellipsis, no 'Read more' buttons on primary content.
The frontend is deliberately minimal — Crimson Pro serif font for passages, a saffron-and-cream palette inspired by YSS aesthetics, and no engagement patterns whatsoever. No streaks, no daily quotes, no push notifications, no analytics. When the backend is waking from sleep, a gentle message tells the user the service is resting — never 'Oops, something went wrong.' Every UI string maintains devotional tone.

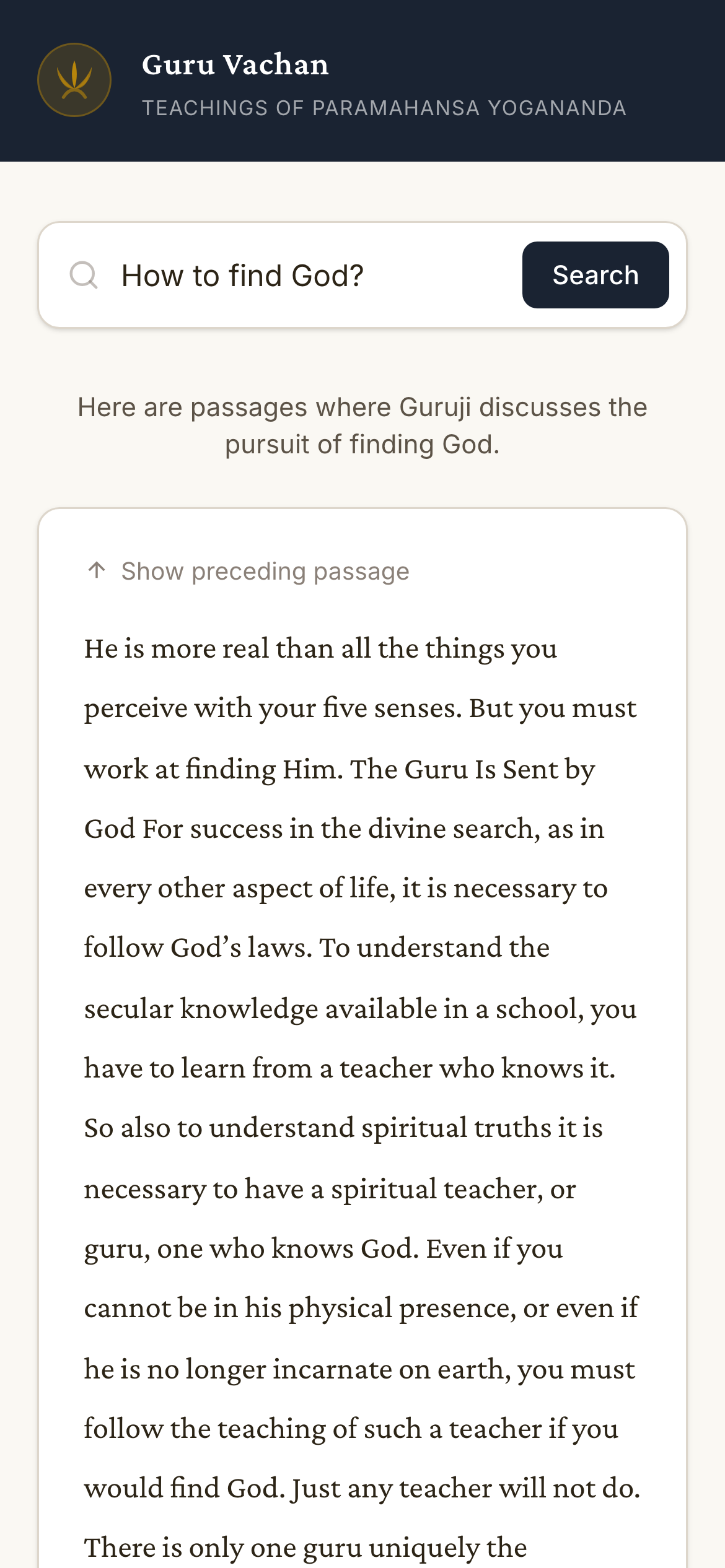
The system indexes 3,500+ passages from Yogananda's public-domain works with 100% text fidelity — verified by automated tests that compare rendered DOM content against source data, character by character. Search latency is under 2 seconds when the service is warm, with intelligent cold-start handling that wakes the backend services gracefully.
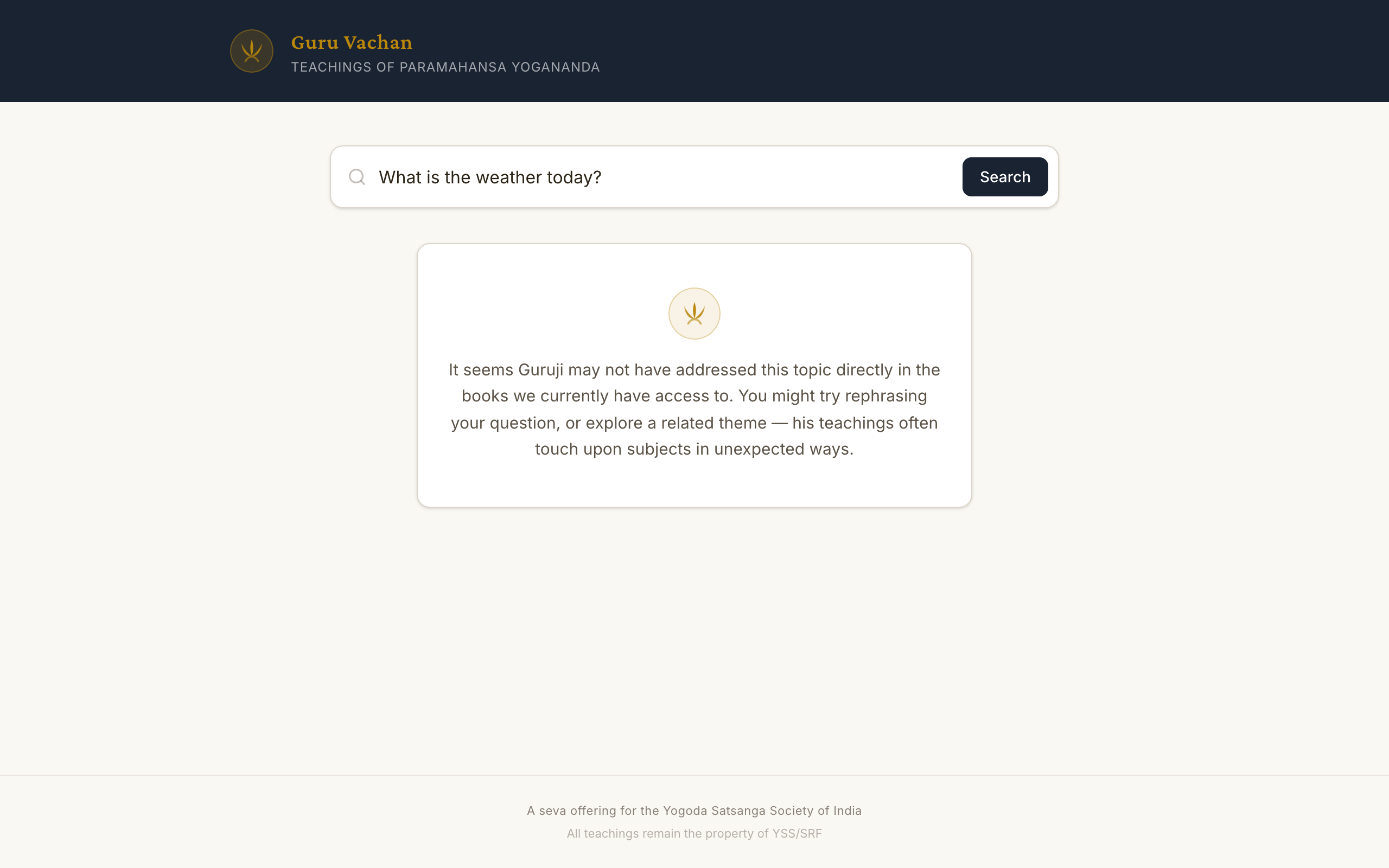
The LangGraph pipeline handles edge cases that trip up simpler systems: metaphorical language ('restless monkey breathes', 'fifty-watt lamp'), multi-author attribution within a single book, and queries in both English and transliterated Sanskrit. The intent classifier is deliberately permissive — it's better to search and find nothing than to wrongly block a valid question about an unusual passage.
The entire production stack runs on Railway for under $5/month, with all services configured to sleep during inactivity. Response compression (GZip), startup workflow pre-building, and API client caching keep the system fast without expensive infrastructure. The frontend achieves sub-second loads with static assets cached for 24 hours.