What is CBDC?
A CBDC abbreviated as Central Bank Digital Currency is the sovereign equivalent of private cryptocurrencies and digital assets like Bitcoin, Ethereum, Solana, and Ripple. It would be issued and controlled by a country’s Central Bank and used by people and businesses for retail payments, much like cash but in digital form. CBDCs will also be used for wholesale settlements in the interbank market.
In simple words, we can say that CBDC is a token on the blockchain and is issued by the central government by which people can do the day-to-day financial activity, Similar to that of fiat currency. For example, the Government of India will issue its own CBDC i.e., an Indian Rupee token similar to any other private Cryptocurrency like Bitcoin, Ethereum, Ripple, Solana, Polkadot, etc.
CBDC represents a new technology and approach for the issuance of central bank money, and can be characterized by the following:
Digital assets: CBDC is a digital asset, meaning that it is accounted for in a single ledger (distributed or not) that acts as the single source of truth.
Central bank-backed: CBDC represents a claim against the central bank, just as banknotes do.
Central bank controlled: The supply of CBDC is fully controlled and determined by the central bank.
There can be two types of CBDC:
Wholesale CBDC: CBDC that would be used to facilitate payments between banks and other entities that have accounts at the central bank itself.
Retail CBDC: CBDC is used for retail payments, for example between individuals and businesses, and is akin to digital banknotes.

Architecture:
Benefits of CBDC:
Cross Border Payments: A central bank digital currency (CBDC) can boost innovation in cross-border payments, making these transactions instantaneous and helping overcome key challenges relating to time zone and exchange rate differences
Enhance existing payments infrastructure: A central bank digital currency (CBDC) will Increase the speed and efficiency of payments while reducing costs and failure rates
Maintain control: Ensure Central Banks retain sovereignty over monetary policy and not allow alternative currencies to dominate the market.
According to the BIS, today some 80% of central banks are looking at CBDC, with the majority of them considering blockchain as the underlying technology. While many of these banks have expressed interest in both wholesale and retail use cases, most of the admittedly few actual experiments or pilots carried out to date have focused on wholesale. These include Project Ubin by the Monetary Authority of Singapore, Project Khokha by the South African Reserve Bank, China’s DC/EB, and Project Stella, a joint research project by the ECB and the Bank of Japan.




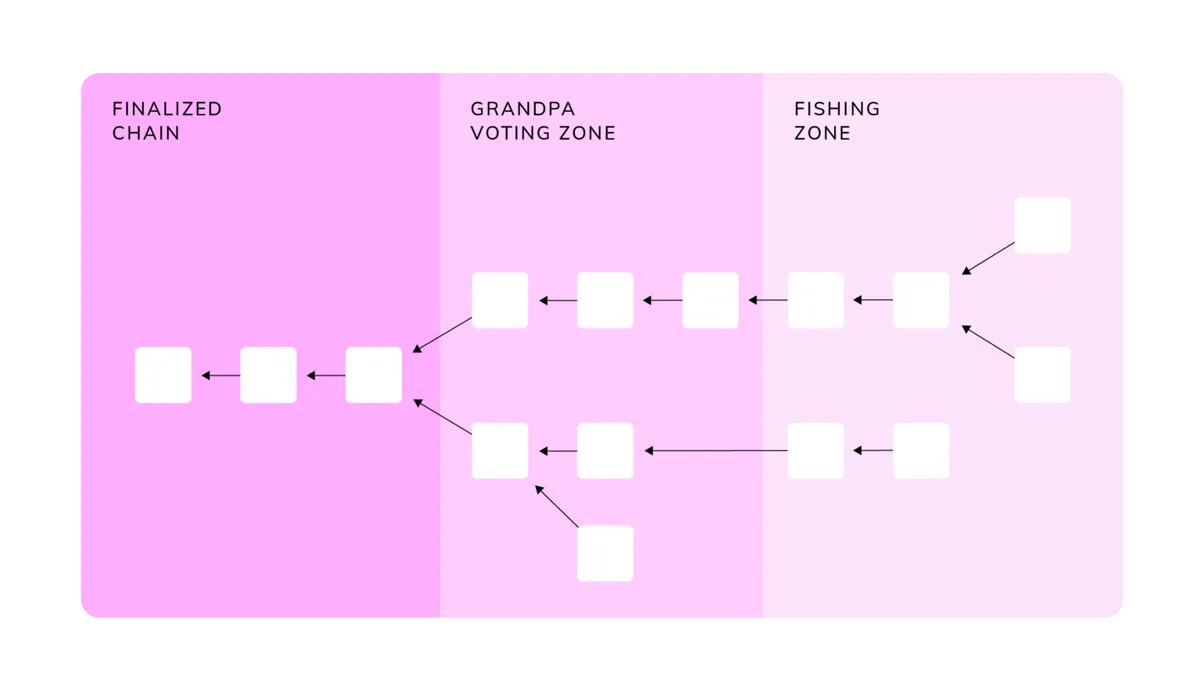
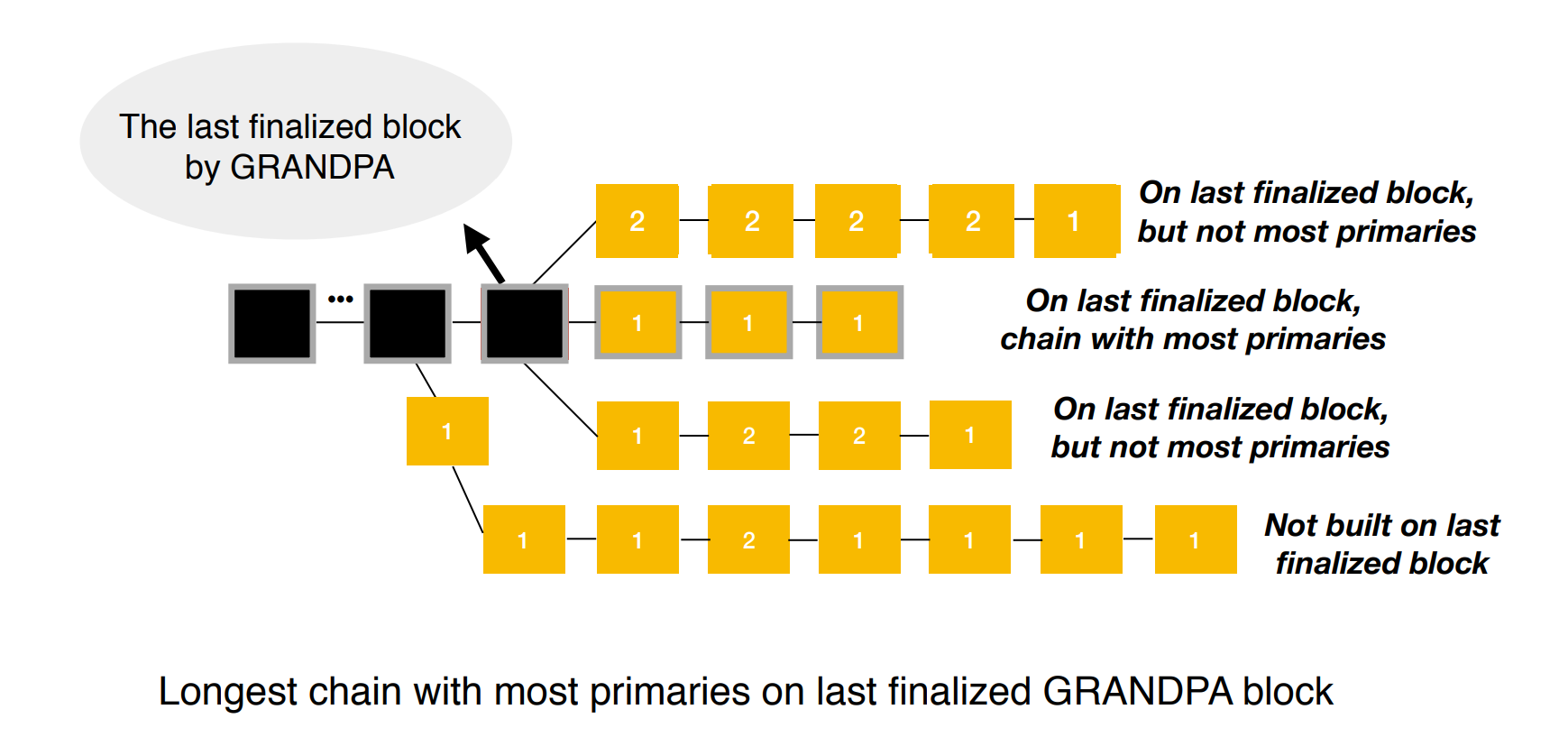
What are Aura, Babe, POW, and Grandpa in Substrate/Polkadot?
It Provides block finalization. It has a known weighted authority set like BABE. However, GRANDPA doesn’t author blocks. It Just listens to gossip about blocks that have been produced by some authoring engine like the three mentioned above.
It works in a partially synchronous network model as long as 2/3 of nodes are honest and can cope with 1/5 Byzantine nodes in an asynchronous setting.
GRANDPA distinguishes itself by reaching agreements on chains rather than blocks, which speeds up the finalization process significantly, even after long-term network partitioning or other networking difficulties.
Each authoring participates in two rounds of voting on blocks. Once 2/3 of the GRANDPA authorities have voted for a particular block, it is considered finalized.

What is Decentralized Identity?
Decentralized Identity is an emerging concept, in which control is given to the consumers through the use of an identity wallet, through which they collect verified information about themselves from certified issuers.
In this article, we’ll be looking at DIDs — what they are, DID documents, Verifiable data, and how they work.
I’d also try to explain why we use DIDs, and what problems they propose to solve.
The problem
Secrets such as passwords, and encryption keys, are used to assist in protecting access to resources such as computing devices, customer data, and other information. Unauthorized access to resources can cause significant disruption and/or negative consequences. Many solutions have definitely been proposed to protect these secrets and in turn, protect the security and privacy of software systems. Each of these solutions, according to research by Zakwan Jaroucheh, follows the same approach, where, once the consumer receives the secret, it can be leaked and be used by any malicious actor. Time and time again, we’ve heard cases of compromised private information, leading to the loss of billions of dollars.
How then can we decentralize secret management, such that the secret won’t have to be sent to the consumer? I guess I can say… This is where DIDs come in.

First, let’s define Identity.
Identity is the fact of being who or what a person or thing is defined by unique characteristics. An identifier on the other hand is a piece of information that points to a particular identity. It could be named, date of birth, address, email address, etc.
A decentralized identifier is an address on the internet that someone, referred to as Subject, which could be you, a company, a device, a data model, thing, can own and direct control. It can be used to find a DID document connected to it, which provides extra information for verifying the signatures of that subject. The subject (which may be you) can update or remove the information on the DID document directly.
For instance, if you’re on Twitter, you likely own a username, take a DID as your username on Twitter. However, in the case of a DID, the username is randomly generated. Other information about you is accessible through your username (DID document), and you have the ability to update this information over time.
Each DID has a prefix that it references, called DID Method. This prefix makes it easy to identify its origin or where to use it for fetching DID documents. For instance, a DID from the Sovrin network begins with did:sov while one from Ethereum begins with did:ethr. Find the list of registered DID prefixes here.
Let’s briefly look at some of the concepts you’ll likely come across when learning about DIDs.
DID Document
In a nutshell, a DID document is a set of data that describes a Decentralized Identifier. According to JSPWiki, A DID Document is a set of data that represents a Decentralized Identifier, including mechanisms, such as Public Keys and pseudonymous biometrics, that can be used by an entity to authenticate itself as the W3C Decentralized Identifiers. Additional characteristics or claims describing the entity may also be included in a DID Document.
DID Method
According to W3C, a DID method is defined by a DID method specification, which specifies the precise operations by which DIDs and DID documents are created, resolved, updated, and deactivated. The associated DID document is returned when a DID is resolved using a DID Method.
Verifiable Credentials
When you hear of verifiable credentials (VCs), what comes to mind? Probably your passport, license, certifications, and any other identification you might have.
This has to do with the physical world. Digitally, if someone wants to verify or examine your identity how can they do this? A verifiable credential in the simplest term is a tamper-proof credential that can be verified cryptographically.
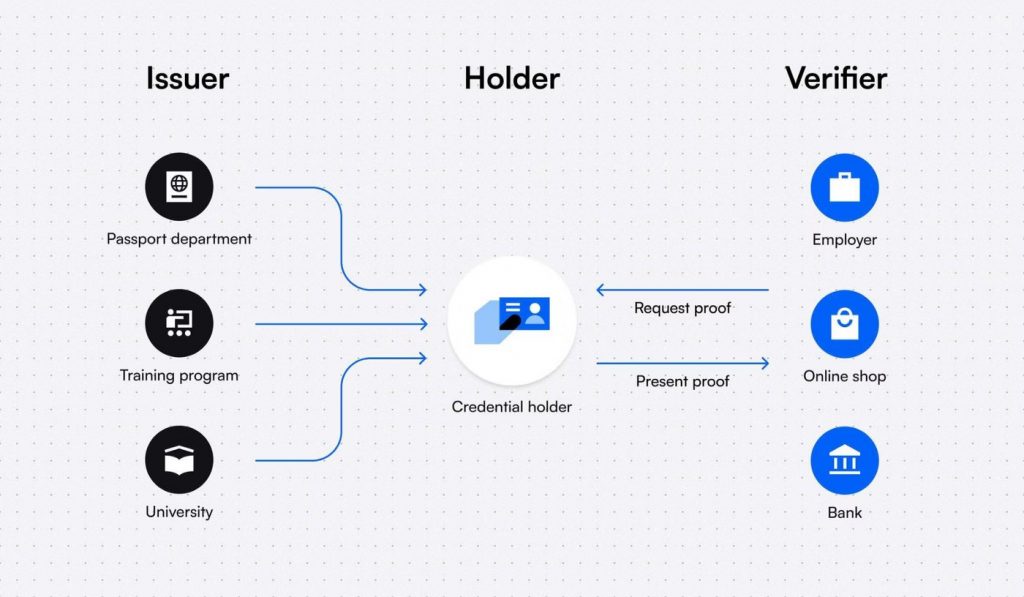
A verifiable credential ecosystem consists of three entities:
- The Issuer
- The Holder
- The Verifier
The entity issuing the credential is known as the issuer; the entity for whom the credential is issued is known as the holder, and the entity determining whether the credential satisfies the requirements for a VC is known as the verifier.
For example, say a school certifies that a particular individual has taken the degree exams and this information is verified by a machine for its authenticity.
Here, the issuer is the school, the holder is the individual who has taken the exam, and a verifier is a machine that checks the verifiable presentation for its authenticity. Once verified, the holder is free to share it with anyone he/she wishes.
I hope you’re able to get it up to this point.
Let’s take a dive into some of the reasons for decentralized identity.
Following his critique of web 3.0, Jack Dorsey, the former CEO of Twitter, introduced the web 5.0 initiative. By claiming that ownership is still a myth since venture capitalists and limited partnerships will take on a sizable chunk of the web, Dorsey highlighted the current constraints in web 3.0. He claimed that web 3.0 would keep a lot of things centralized, necessitating the creation of web 5.0.
One of the prime use cases for web 5 is empowering users with control of their identity, which we all refer to as Decentralized Identity, used interchangeably with Self-Sovereign Identity (SSI. It is an approach to digital identity that gives individuals control of their digital identities. Why did Jack introduce web 5? Why do more people want to take back control of their data through decentralization and blockchain? What benefits does this hold for people and organizations?
Benefits of decentralized identity for Organizations
- Decentralized Identities allow organizations to verify information instantly without having to contact the issuing party, like a driver’s licensing organization or university, to ensure that IDs, certificates, or documents are valid. It takes a lot of time, sometimes, weeks and months to manually very credentials, which slows down recruitment and processing times while using a lot of financial and human resources. By scanning a QR code or putting it through a credential validator tool, we can quickly and easily validate someone’s credentials with DIDs. Here is a typical example of how a company can leverage decentralized identity technology to hire efficiently:
* Anita, a job applicant, manages her decentralized identity and Verifiable Credentials on her phone with a Wallet and wants to apply for the company looking for a community manager. * She attended a boot camp that gave her a community management degree that she keeps in her digital wallet as a Verifiable Credential that can't be faked. * The company makes a job offer and they just need to check that her certificate is authentic. * The company requests her data and she is prompted on her phone to give authorization to the company to show her certificate * The company receives a QR code and simply scans it to instantly confirm that her community management certificate is authentic. * They offer Anita the job.The traditional, manual verification process would have taken several weeks or months to achieve the same outcome.
- DIDs enable issuing organizations to conveniently provide Verifiable Credentials to people and prevent fraud which in turn, greatly reduces costs and increases efficiency. Many people, even in positions with a lot of risks, use forged or fraudulent certificates to apply for jobs. A university can issue fraud-proof credentials, which the recruiting organizations can easily verify, thereby reducing the possibility of forgery.
Benefits of decentralized identity for Individuals
- Decentralized identity increases individual control of identifying information. Without relying on centralized authority and third-party services, decentralized IDs and attestations can be validated.
- People can choose the details they want to share with particular entities, including the government or their employment.
- Decentralized identity makes identity data portable. Users can exchange attestations and IDs with anybody they choose by storing them in their mobile wallets. Decentralized identities and attestations are not stored in the issuing organization’s database permanently. Assume that someone called Anita has a digital wallet that helps her to manage authorizations, IDs, and data for connecting to different applications. Anita can use the wallet to enter her sign-in credentials with a decentralized social media app. She wouldn’t need to worry about making a profile because the app already recognizes her as Anita. Her interactions with the app will be stored on a decentralized web node. What Anita can do now is, switch to other social media apps, with the social persona she created on the present social media app.
- Decentralized identity enables anti-Sybil mechanisms to identify when one individual human is pretending to be multiple humans to game or spam some system. I t frequently becomes impractical to log in several times without the system noticing a duplicate as the user will need to use identical credentials each time.
Conclusion
Decentralized Identity has a lot of pros, and so many individuals and organizations are already keying into it. A lot of companies like Spruce ID, Veramo, Sovrin, Unum ID, Atos, etc have worked hard to create decentralized identity solutions. I hope to see where these efforts lead and look forward to seeing DIDs become more used in a bunch of applications as well.
For further reading, feel free to check out these resources
- https://identity.foundation/faq/
- https://www.gsma.com/identity/decentralised-identity
- https://venturebeat.com/2022/03/05/decentralized-identity-using-blockchain/
From the article of Amarachi Emmanuela Azubuike

Understanding Basic Substrate Code
- ChainSpec.rs: The chainspec file is responsible for the initial fundamental root of the chain. From there we can do the following things:
- We can add or manage accounts that we will get during the starting of the chain.
- How We can generate a new account.
- We can pre-fund the account. So that we can make transactions on the chain.
- We can add any other prerequisite related to any pallet if the pallet needs it.
- Basically, we can do everything which we need on the chain during starting(Block 1) of the chain.
- Cli.rs: The cli file is responsible for all the customization of commands to interact with the chain. Like
- How the block will generate instant-seal, manual, or default.
- How we can build the spec for the chain, purge the chain, and many more.
- Basically whatever we can do with the chain by the help of commands.
- Command.rs: It is the extended or helper file of the cli one.
- Main.rs: It is the main file just for instantiation purposes of cli.
- Rpc.rs: The RPC file is responsible for all the methods or customization related to RPC(Remote Procedure Call). Like
- How the block will generate instant-seal, manual, or default.
- How we can build the spec for the chain, purge the chain, and many more.
- Basically whatever we can do with the chain by the help of commands.
- Service.rs: The service file is responsible for the main business logic for the block generation. Like
- Consensus protocol.
- How the block will generate differently for the different commands like manual, or instant seal.
- How the chain will interact between nodes.
- And all the things related to the database, telemetry, RPC, finality, and much more. It basically takes the configuration from the Runtime module which we do with respect to any pallet.
- Runtime: The Runtime is responsible for the coupling and config customizations of the pallets. It has the lib.rs which has the main code and also the benchmarking and other files also come in it.
- Lib.rs: This is the file where we can do the coupling and customization. Let’s understand one by one:
- Firstly it has all the basic configurations related to runtime like chain name, chain version, etc.
- We need to customize/implement all the pallets we are using in the chain. Like frame_system, grandpa, aura, timestamp, sudo, etc
- We create the chain runtime by adding all the pallets into it.
construct_runtime!( pub enum Runtime where Block = Block, NodeBlock = opaque::Block, UncheckedExtrinsic = UncheckedExtrinsic { System: frame_system, RandomnessCollectiveFlip: pallet_randomness_collective_flip, Timestamp: pallet_timestamp, Aura: pallet_aura, Grandpa: pallet_grandpa, Balances: pallet_balances, TransactionPayment: pallet_transaction_payment, Sudo: pallet_sudo, } ); - Lib.rs: This is the file where we can do the coupling and customization. Let’s understand one by one:
- We can also add more business logic respective to any pallet or node.
- We also implement the different traits for different transactions on the node. Like execute the block, finalize block, validate transactions, etc.
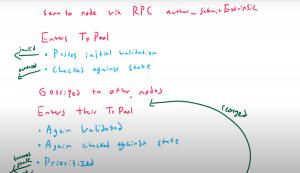 Basically, we can customize the block on two levels: Level 1: At this level, we can only do the validation customizations and these can be done in the pallet. Level 0: On this level, we can customize the structure or basic behavior of the block. We can segregate these customizations into two parts.
Basically, we can customize the block on two levels: Level 1: At this level, we can only do the validation customizations and these can be done in the pallet. Level 0: On this level, we can customize the structure or basic behavior of the block. We can segregate these customizations into two parts.- Type 1: The changes we covered on the service .rs
- Type 2: The changes which we can make from runtime.
- We can update the time of the block generation from the configuration of the timestamp pallet. Same as we can do more customizations with the help of other pallets.
- We can customize the block in the transaction pool.
- We can add the conditions/validations in the different block transaction methods like execute the block, finalize block, etc.
- Above changes, we can do in the implementation of the traits related to it. Along with that if we want to customize the block we can look at the other methods in the traits of the executive file(link).